
### Repository https://github.com/jnordberg/dsteem
You will learn how to:
- Get/filter thousands of Discussions from the Steem blockchain.
- Inspect the Account object.
- Calculate the dynamically changing Steem:Vest ratio.
- Interact with Steem without the complications of Node.JS
- Showcase the advantages of asynchronous JavaScript programming.
Requirements
- HTML
- JavaScript
Difficulty
- Intermediate
Curriculum
Part 0: Steem Tutorials Are Severely Lacking Part 1: Sorting New Tab Part 2: Hello World Part 3: Dissecting Discussions
Proof of Work Done
https://gist.github.com/edict3d/9f6358f850449f9d9a4ee633bac5ac23

This tutorial will incorporate the things we learned from the previous lessons. Steem is the first social media platform to give us full access to the underlying infrastructure. Decentralization has the disadvantage of being impossible to regulate (e.g. banning bots), but this flaw can be flipped on its ear.
Using the Steem API, we can control the content displayed using filtration and sorting techniques. From my GitHub copy/paste StakeSterilizer.js and StakeSterilizer.html into the same folder on your computer.
Open the html file in your default browser (I use Chrome), open the console (F12), and click the "Retrieve!" button. It should look something like this:
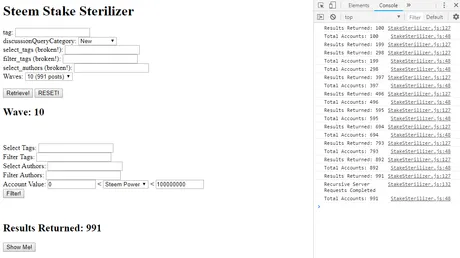
You just grabbed 991 posts from the 'New' tab. You can now click the show button to show them or filter them down to a lower number. You could also click the retrieve button again to grab another 991 posts from the 'New' tab.
There is some kind of polynomial efficiency issue with buffering where it only takes a few seconds to display around 1000 posts, but it takes ten times as long to display 3000. It only gets worse the higher you go. This is why I created the "Show Me!" button: to give users a chance to filter down the results. If there are 200 or less results they will show automatically.
What's happening under the hood?
The dsteem API only allows 100 posts to be requested at a time. Therefore, to get more I've implemented a wave system that grabs 100 posts, then grabs 100 more posts starting at the bottom of the last list.
This allows us to recursively call getDiscussions() in the callback. During every step of recursion the HTML menu box "waves" (start line 41 in HTML file) gets decremented by 1. When the waves menu reaches a value of 1 recursion ends and the value of waves gets reset back to its original number (for convenience).
On line 63 of of StakeSterilizer.js in the getDiscussions() function:
if ( !(allDiscussions === undefined || allDiscussions.length == 0) ){ var lastDiscussion = allDiscussions[allDiscussions.length-1] start_author = lastDiscussion.author start_permlink = lastDiscussion.permlink }
This is the code that makes recursion possible. Because the Steem API has provided us with the start_author and start_permlink attributes, we can set them to the end of the previous wave.
broken!
You'll notice some redundancies in my code. Specifically, select_tags, filter_tags, and select_authors are broken. It took me a while to figure out, but attempting to use these optional client.database.getDiscussions() attributes yields completely undefined behavior. You can't count on accurate results in the least bit. I'm not ready to complain about this yet because Hard Fork 20 is right around the corner and I hear there are going to be a lot of changes. Apparently this has been a known issue for over a year.
It wasn't that hard to add this functionality to my filtration section. The disadvantage to this is that our computer has to do the work instead of the witness node. If it worked, the witnesses would provide us a lot more data to filter and we could find more valuable content in a quicker time span. I'm guessing a lot of the API functionality was cut because of all those lag problems we had some months ago. More on this later.
Other Options
You'll notice on the discussionQueryCategory: menu option that we don't have to fetch just posts from the 'New/Created' section. I added all the options:
DiscussionQueryCategory: "active" | "blog" | "cashout" | "children" | "comments" | "feed" | "hot" | "promoted" | "trending" | "votes" | "created"
'Children' returns posts that have the most comments. 'Votes' returns the posts that have the most votes (regardless of how powerful the votes are). 'Comments' gets the comments of a specific author (same as the tab found on Steemit.com). 'Cashout' gets posts that are close to receiving payment (you could use it to get in last minute flags for bad content. Note: you can't upvote a post in the last 12 hours before cashout. STEEM_UPVOTE_LOCKOUT_HF17)
Feed Peeking:
If I had to pick the best thing about the Steem API in this context, it would definitely be the ability to snipe the feeds of other users. Try it yourself. Type in the username of anyone on Steem in the tag: field and switch the discussionQueryCategory: to 'feed'. You'll be able to see the last 500 or so posts that appear on that user's feed.
I've already found a lot of interesting bloggers by sniping the feeds of @krnel, @taskmaster4450, @fulltimegeek, @zoidsoft, @greer184, etc.
For simplicity of this tutorial, I decided to focus on functionality over style. Discussions are displayed with the raw Date data followed by a simple link to the article on Steemit.com
function displayDiscussions(discussions){
for(var i = 0; i < discussions.length; i++){
var discussion = discussions[i]
var link_text = discussion.title
if(link_text == ""){
link_text = discussion.body.slice(0, 80)
}
var link = " <a href='https://steemit.com"
+ discussion.url + "'target='_blank'>"
+ link_text.slice(0, 80) + ""
results.innerHTML += discussion.created + link +"
"
}
}
'Cancel Waves!' button
This button appears during recursive retrieval. Pushing the button will end recursion manually so you don't have to wait for the waves to complete.
This button is a good example of why JavaScript can get more complicated than other languages. The asynchronous nature of JavaScript allows the web page to not freeze while we are making server requests. In essence, this dynamic mimics the execution of a program that is using multiple threads. However, JavaScript remains single-threaded.
I wanted to add a loading graphic, but that is beyond the scope of this tutorial and would overcomplicate things.
Reset button
Make sure to hit the reset button and clear all your arrays if you want to change the tag: or discussionQueryCategory:
If you don't then start_author and start_permlink will populate with the old data and it won't work.
Probable index on 'New' requests.
You'll notice that retrieving posts from the 'New' tab is a lot faster than retrieving posts from any other section. I assume this is because the 'New' tab is indexed on the witness nodes to make them faster.
Also, the 'New' tab is static. The order remains the same no matter what, making it easy to index. The hot/trending/promoted tabs are constantly in flux which likely makes it harder for the witnesses to dish them out as fast.
Asking a node for 'New' posts under a specific tag yields the same slower outcome, so it is likely that only a 'New' request with no filter is indexed for faster results.
Filter!
It's not hard to hit the Retrieve button 6 times in a row and receive 6000 posts from a blockchain node. Make sure you don't click the button before the previous waves have finished, or there will be weird asynchronous action that returns lots of duplicate posts.
With my primitive code there is no way to display 6000 posts. It would take way too long and likely just freeze the browser. Therefore, we are expected to filter that number down to something more reasonable like 1000 or less.
-
Separate all authors/tags with a single space just like you would when writing a blog on Steemit.com.
-
The "Select Tags:" filter will delete all posts that don't match at least one of the listed tags.
-
The "Filter Tags:" filter will delete all posts that match any of the listed tags.
-
The "Select Authors:" filter will delete all posts that are not written by the authors that you specify.
-
The "Filter Authors:" filter will delete all posts that are written by the authors that you specify.
These filters compensate the Steem API's broken ones. Hopefully hard fork 20 eliminates the need for them. All the filtration logic can be found in the filter() function starting at line 152 in the .js file. The text field is imported with document.getElementById() and then .split(" ") to create an array. It is then .filter(Boolean) to remove empty strings.
var select_tags_filter = document.getElementById( "select_tags_filter").value.split(' ').filter(Boolean)
I decided to add my own filter that would remove posts based on account value. Currently the only option in the menu is Net Steem Power, but that will change in the future. In order to calculate account value I had to add code to additionally request the account of every discussion's author we received. This call is pretty inefficient because if we grab 500 posts from the same author we'll also ask the server for 500 copies of the same account. However, the asynchronous nature of JavaScript seems to work in our favor here. The speed of the application isn't effected by this lazy code.
function pushAccounts(accountNames){ /* * Push 99 more accounts onto allAccounts[]. */ client.database.getAccounts(accountNames).then(function(accounts){ for(var i = 0; i < accounts.length; i++){ var account = accounts[i] allAccounts.push(account) } console.log("Total Accounts: " + allAccounts.length) }) }
At first glance the Account object looks like it's full of a ton of useful information, but it actually isn't. Most of the arrays are empty including guest_bloggers, market_history, other_history, post_history, tags_usage, transfer_history, and vote_history.
Again, I assume that these cuts were made to put less stress on the blockchain nodes. Seven months ago when I had very little Steem Power I wasn't even allowed to transact on the blockchain because bandwidth was being cut every morning. I had to wait until the afternoon rolled around.
We'll have to see if HF20 changes any of these things. It's very cluttered and disorganized.

For example, delegated_vesting_shares and received_vesting_shares are mislabeled. They should be called vesting_shares_delegated and vesting_shares_received. Everything gets listed in alphabetical order, so these name changes would put them into the 'vesting' block of attributes where they belong.
Both of these attributes, in addition to vesting_shares, are required to calculate Net Steem Power. To make this calculation we also need to know how much Steem is in a single Vest. Apparently, this number changes all the time. It constantly gets bigger, which is how we are granted that ~15% interest from the reward pool (witnesses 10%, upvotes 75%).
I wrote this little script to figure it out. Open it as an HTML file and type any username into the text field. Hit F12 to open the Chrome console and you'll see the Account object in the log.
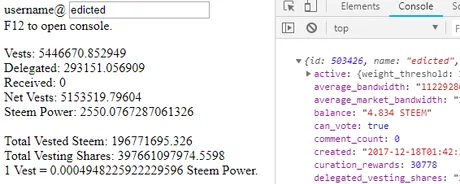
To calculate the Steem:Vest ratio we must call the client.database.getDynamicGlobalProperties() function. From here, take the (result.total_vesting_fund_steem) and divide it by (result.total_vesting_shares).
Currently:
1 Vest = 0.0004948223407748679 Steem Power.
This number continues to grow, giving us interest on our Steem Power.
Using this "constant" we can take
(vesting_shares - delegated_vesting_shares + received_vesting_shares) * STEEM_VEST_RATIO
var totalVests = vests + received - delegated
p.innerHTML += " Net Vests: " + totalVests
+ "
Steem Power: " + totalVests * STEEM_VEST_RATIO
}
})
}
function getSteemVestRatio(){
client.database.getDynamicGlobalProperties().then(function(properties){
var steem = parseFloat(properties.total_vesting_fund_steem)
var vests = parseFloat(properties.total_vesting_shares)
p.innerHTML += "
" + "Total Vested Steem: " + steem
+ "
" + "Total Vesting Shares: " + vests
+ "
" + "1 Vest = " + steem / vests + " Steem Power."
STEEM_VEST_RATIO = steem / vests
})
}
Seems like an awful lot of work just to figure out how much Steem Power is going into a particular user's vote. You'd think this number would just be included with the account... but again... who knows what's going to happen with HF20.
Using this logic I was finally able to implement the filter. You can use it to filter out people that don't have a lot of stake, or you can use it to filter out people that have a lot of stake (or anything in between). I was happily surprised to find out that Steem is a lot more decentralized than I thought it was. A lot of the accounts that are posting content these days have obviously made an investment in Steem or have simply received some good rewards over the time they've been here. Now that the market has bottomed out only the true believers remain.
Conclusion (Tutorial Over)
I hope I was able to help anyone looking to further their education of the dsteem API. I look forward to HF20 and anticipate that much of the documentation and empty variables will be changed for the better.
My journey continues on attempting to create apps using nothing but dsteem and JavaScript. In the future I'll be releasing modules that allow anyone onboard my team as we grind forward together. I will create value out of thin air by piggy backing off these blockchains that have created value out of thin air. I will strive to create games, reputation systems, and content filters that are owned by the community rather than myself.
To infinity, and beyond!
This filter I've created isn't that functional, yet. Someone pointed me in the direction of https://steemlookup.com/#/
This is very similar to the work I'm trying to get done, but it just isn't good enough in this form. Also, it's clearly centralized through a server hosting the steemlookup website. We should be looking for decentralized solutions (although full decentralization is highly inefficient).
I'll be working to make this filter more functional and look a lot prettier. The goal of the Steem Stake Sterilizer is self-explanatory: I'm looking to mitigate the negative effects of vote buying and high-powered exploitative whales on the platform. In addition, I want everyone to be able to view Steem through a different lens, just like Facebook's wall that made it popular so long ago. In effect, the goal of the Steem Stake Sterilizer is to enable custom trending tabs and link up to a decentralized reputation system that rewards positive interaction with community trust.
The biggest missing piece from this filter is the ranking system. I'm going to allow users to create custom white/black lists that effect the sorting order of posts.
Think haejin doesn't deserve to be on your trending tab? Throw his self-voting accounts on a blacklist so his name will only pop up if he actually gets votes from a different source. Tired of being exposed to posts that bought their votes? Blacklist nerf all the vote sellers so that their stake only counts for one tenth the value it counts for on Steemit.com. Do you know someone who you trust who always has something important to say? Multiply/add stake to their username so they appear higher on the list. Do you think posts that deny their own reward should be rewarded with increased visibility? Multiply the stake of posts that dont allow_votes by a custom multiplier.
This is the kind of functionality I'm looking to bring to the Steem blockchain, and I'm just getting started.
Return from dsteem Tutorial Lesson 4: Steem Stake Sterilizer (Discussion Filtration) to edicted's Web3 Blog