

Shifting focus!
So for the past few years I've been tinkering with JavaScript and the Condenser API; learning a few things here and there. Until now I've been avoiding Node.js like the plague because I didn't want to add any extra complexity to my plate.
Unfortunately, I'm starting to realize that NOT using Node.js has likely ironically done exactly the opposite of my intent. By not utilizing this technology, I'm running into problems that I shouldn't have; completely unnecessary bumps in the road due to purposefully omitting tools from the toolkit.
Last nail in the coffin.
Plain and simple: In order to make sense of the sprawling information Graphene has to offer (i.e. blockchain blocks), you must have a database to organize said information and permanently store it. In the case of Hive, all the full nodes are running Condenser, which means we can connect to any full node and query it in a standardized way and get back the information we're looking for using that same standard.
The problem with Condenser, as stated in previous posts, is that it's a heaping pile of hammered dogshit! It was thrown together very quickly and was mostly made to cater to our social media blogging application. Once it actually worked, developers moved on to other things, leaving behind the spaghetti factory that is Condenser.
Spaghetti Factory
While spaghetti factories are fun to build, they do not scale up, like at all. When you build something like this, you are just trying to get the thing up and running as fast as possible one piece at a time. At a certain point you realize, "Oh shit! I might need to start over from scratch if I want to scale up much bigger than this... yikes!" Welcome to programming.
So why don't we fix it?
Nobody really wants to fix it! If it's not broke, don't fix it! Amirite? Steemit Inc was always trying to push forward and increase token value with SMTs and whatever else. Who's going to pay for that? People don't like working for free.
Of course we have the Decentralized Hive Fund, which is nice. However, we'd still need to find a programmer willing to do the work that actually has experience. Spoiler alert: the subset of people on the entire planet with c++ experience and Condenser experience is like, I don't know... less than a dozen. The subset of those people who actually want to fix condenser? Zero! It's not a fun job; It's busy work. I guess we need more code monkeys!
Reasons to not fix it!
Let me give an example here so it makes more sense. Say I created a totally decentralized game that allowed anyone to connect to a full node and play that game by proxy through the full node using nothing but someone else's server and the Hive blockchain. This honestly has been my goal from day one.
Now imagine that game gets popular. Normally in a situation like this I'd be running a centralized server and processing all the transactions myself. However, because I'm piggybacking off the full nodes I'm forcing them to bear the burden of all that bandwidth. One of two things is going to happen.
- Full nodes start rejecting users who are trying to play my game because it is melting their server and costing them money without giving them anything in return. One by one all full nodes ban my game, forcing me to boot up my own server if I want to keep the project going.
- The game is creating so much FOMO that the price of Hive has increased significantly and full node operators are willing to accept these bandwidth costs for the good of the network. Seems unlikely considering they could just ban the game and take the short-term gains, hoping that other full nodes won't ban it.
Purpose of a full node.
A full node is a database connected to the blockchain that provides users that connect to it with relevant useful information. Unfortunately, the most useful and valuable information on the blockchain resides in custom JSON operations (apps created by random developers). Condenser does not organize these custom operations in any kind of meaningful way, meaning you can't ping a full node to get the information you want if you are trying to build a decentralized service. Instead you must create a custom node that organizes the data and allows your users to connect to it.
In a way this increases decentralization, as now their are more servers connected to our blockchain. On the other side of the coin, the network becomes more centralized because only one node can process the information instead of any full node being able to do it. Do we really want our full nodes to be 'dumb'? Not really.
It is also "possible" to make an application (extremely hackish) that gets around this by not using custom JSON at all. I got my @smartasscards game up and running in the beginning by storing the information directly on chain using comments... check it out:
https://peakd.com/test/@smartasscards/test6
Wow! That was 30 months ago! Yikes!
Now this solution is extremely inefficient. IIRC it costs 20 times more Resource Credits to post a comment to the blockchain compared to a custom JSON operation. This is because comments can be upvoted and custom JSON can't, so eventually every node on the network would be calculating upvotes, payouts, and curation rewards on a comment where no such work is done on custom JSON. In addition, there is an extra burden to the full nodes if other apps and services ask for information regarding that comment, whereas queries for custom JSON do not exist (yet).
The one cool thing about this solution is that I could play a multiplayer game over the internet without even having to run my own server or pay for anything... which is pretty crazy when you think about it. Unfortunately, that's also the exact reason why such a solution could never scale up and go viral. Full node operators would probably not allow me to leech off of them like that for long. Maybe I'm wrong.
Referral code.
I do have a potential solution to this problem. The governance token I plan on creating will have a referral code that gives 10% of the governance tokens to the referrer. If this code was pointed toward the full node conducting the transactions they'd have a financial incentive to allow bandwidth to be leeched from their server.
Moot Points
None of this matters because I need to get the game up and running myself first. In order to make the governance token I also need to create an entirely new consensus algorithm (proof-of-burn). I can't use HiveEngine for this because it's a completely different token model. Sounds like a lot of work, but actually my vision of POB² is very simple (more on that some other day) and I don't think it will be that difficult.
Regardless, all of this requires a database, there is no other way around it. Luckily, I have a tiny bit of experience with databases from way back in college and when I was trying to play poker online using my own custom algorithms. I definitely need a refresher course, but relearning something you already used to know is a lot easier than starting from scratch.
What was the point of this post again?
Oh right! Yes, in any case, I'm making a tiny bit of progress getting this all started for realz. I've finally booted up a virtual server on my computer (localhost) using Node.js. The tutorials for Node.js and running a server are actually way way more simple than I thought they'd be! Kinda embarrassing I haven't started this sooner. So much to do, so little time.
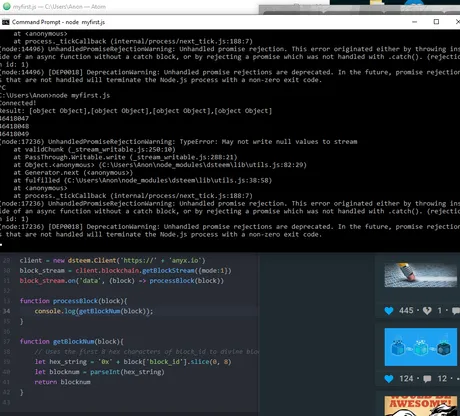
So now I'm in a place where I have my virtual server, I've connected it to MySQL database, and I've connected it to @anyx's full node and was able to start streaming blocks directly from the blockchain. Pretty cool.
Unfortunately, we can see that error above: TypeError: May not write null values to stream... so my stream is getting cut off because it's receiving blank values. Not 100% sure what's going on there but I assume my bandwidth is being cut. As stated earlier, running a server can get expensive. I likely need to change the way I ask for block info. No problem.
Conclusion
Things are starting to come together. The database I create to parse Hive blocks will be the foundation of EVERY dapp I bring to this community. Once I have the solid foundation of a functioning database with all the required block information, things should start progressing at a much nicer pace. Programming is all about recycling code and creating reusable modules. Hopefully I've been at this long enough to have some semblance of order. My speghetti factory awaits construction!
Return from Making Some Progress to edicted's Web3 Blog