

I have a lot to talk about, but I'm not really sure where to start.
I'll probably have to break up everything into several posts.
I guess we'll see how far I get this time around.
I've been thinking a lot about a token I'd like to bring to the network.
Not an SMT or a HiveEngine token; something much simpler than that with no curation or ability to upvote. The inflation would be created much more consistently and predictably, even moreso than POW.
POB (Proof-Of-Burn)
Unfortunately, it's hard to call it that because of the whole Proof-Of-Brain debacle. However, since Proof-Of-Brain isn't actually a real thing (certainly not a consensus algorithm, and never will be) I think it's fair to say that the term proof-of-burn will greatly overshadow proof-of-brain and will eventually rightfully snipe the acronym for itself.

What is proof-of-burn?
This is not a new idea, in fact @fulltimegeek once talked about the exact concept in reference to a project called Vaporchain (back when it made sense to call it that on the STEEM blockchain). I remember saying something like, "Sounds like vaporware..." I guess I was right, as I have to assume the project has been abandoned. Why is that?
How does HiveEngine do it?
HiveEngine is a centralized service creating tokens on a single node. We have to trust that node to do all the work and keep everything within the bounds of consensus. I'd like to think that project operators like @khaleelkazi (founder of Leo) would find a way to keep the token alive if HiveEngine went rogue, but there are really no guarantees.
In addition, even if the founders of the respective tokens did manage to keep their projects alive in the wake of such a doomsday scenario, irreparable damage would be done to many projects and rollbacks of "immutable" projects would be quite likely to remove the actions of the bad actor.
Sounds like we need multiple nodes in consensus for secure redundancy...
Indeed, wouldn't that be nice. So why hasn't this happened yet? Why aren't more witnesses running the HiveEngine code and creating a decentralized network for tokens?
Because they can't.
Coins on HiveEngine are transferred via custom JSON operations. As per Hive consensus rules, any user can post any custom JSON they want to the blockchain and that operation will be considered valid by the Hive network.
To give the most relevant example:
Imagine I post a custom JSON operation to the Hive network that says I'm going to transfer 1,000,000 Leo tokens to another account (that I also control). I don't have this many liquid Leo tokens, so clearly this should not be allowed. However, the witness nodes don't know or care about this; they allow the transaction to appear on the next block.
Because HiveEngine is only running a single node this isn't a big deal. Their node knows this is an invalid transaction and just ignores it. However, what would happen if we had multiple HiveEngine nodes running?
Imagine I was the one running a separate HiveEngine node and the same transaction occurred. I could simply program my own node to allow the transaction to complete, creating coins out of thin air and allowing my old account to accrue a negative balance.
Now I'm running a fork; a fork that has no value, because it only benefits me and allows me to create coins out of thin air. However, no one knows I'm running a fork. They do not have access to my node. They don't know I have accepted the bogus transaction as valid. It's just sitting there on the blockchain, and everyone has to just assume it was invalidated by the nodes running the HiveEngine code.
At this point, anyone who trusts my node and connects to it thinks they are interacting with the LEO coin, but in reality they are buying/selling a corrupted token that should have never been allowed to exist. The only way to know something catastrophically wrong has occurred would be when someone tried to cash back out to Hive and wasn't able to.

Haven't even talked about the Hive peg yet.
This is another huge reason why multiple HiveEngine nodes could never be run in consensus given the current setup. All the Hive on the entire HiveEngine network is centralized to a single account for simplicity. If you tried to sell your funds on anything but the main node that node would have to ask permission from the main node to get the job done, as only one entity has access to the @honey-swap account.
There are obviously a lot of problems creating tokens on the Hive network in a permissionless way. The "simple" solution is to get permission. This involves creating a hardfork for Hive that includes the token rules directly into the consensus layer, forcing all witnesses to obey the rules and not allow bogus transactions to appear on our blocks in the first place.
Of course, the technology that I'm talking about here is SMT. HiveEngine will likely forever remain a centralized service best utilized for quick prototyping and testing. Maybe I'm wrong and it will evolve into something else, but do we even want that? Prototyping is just as important as any other stage of development; they are all necessary.

Distributed Proxy Nodes
I believe the solution to this problem (and many many others) is a technology I'm currently referring to as proxy nodes (perhaps lite-nodes). Anyone who wanted to be a member of this new network would essentially be forced to run their own node and validate the transactions locally on their own machine, thereby avoiding all of the security issues involving trusting another source for information.
Is that practical?
It might sound EXTREMELY inefficient and expensive to tell everyone they need to be running a node. That might be the case. We've all seen the witnesses complaining about server costs and whatnot.
However, the thing that is expensive about servers is bandwidth. If 1000+ users are querying your node for large sets of information, of course this could start getting expensive quickly.
The nice thing about proxy nodes is that we can avoid all of that nonsense. Your proxy node exists only for you. No one will be allowed to connect to your node and ask it questions (database queries). The only entity that would be interacting with this database would be your local machine itself.
This limits the amount of bandwidth required to the size of the blocks themselves, which are actually quite small. In fact, the current maximum size for blocks is something like 65k (most are much smaller than this). Remember that one time I filled up an entire block with garbage just to see if I could?
https://peakd.com/steemdev/@edicted/65-kb-max-length-post-keywords-javascript-steem-api
LOL
What a way to spend Christmas 2018.
Seriously look at the date... Dec 25... ha.
To give an idea of how inefficiently we are running things here...
Do you have any idea how I was able to find an 18 month old post so quickly and make reference to it in my current blog? I use a script that I wrote ages ago:
https://peakd.com/utopian-io/@edicted/dsteem-tutorial-lesson-4-steem-stake-sterilizer-discussion-filtration
Honestly, it's amazing that this script still works perfectly after almost 2 years:
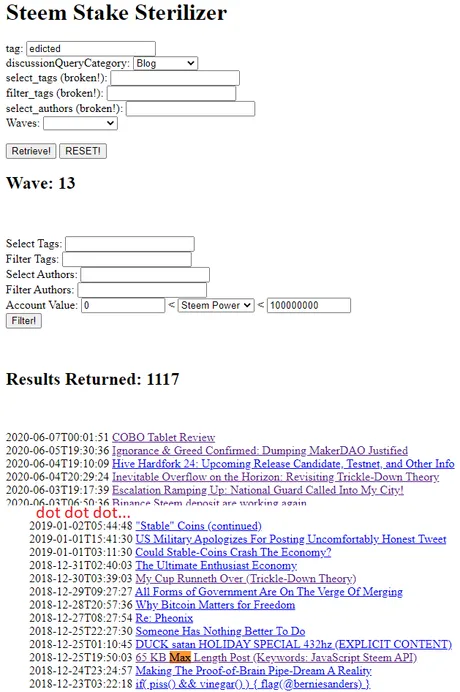
So what am I doing here?
Well, I'm connecting to a Hive node (thanks @anyx) and asking it to send me the links of EVERY SINGLE POST I've ever published over the last 2.5 years. This way I can CTRL-F find the post I'm looking for and make reference to it. I make this request like all the time. If that's not inefficient than I don't know what is. I am theoretically costing @anyx money and bandwidth to run this extremely inefficient function time and time again.
If I was running a proxy node I could perform this database query for zero bandwidth cost because all of the information is stored locally on my machine. The only bandwidth costs I would incur would be downloading blocks, and again, this is an inexpensive operation. Once I have the blocks I have them forever and I can perform infinite database operations for zero bandwidth costs. Last time I checked our entire blockchain was less than 300GB.
Do I need all the blocks to run a proxy node?
Absolutely not. In fact, many of the functions of a proxy node (like creating a feed or trending tab) would only require the last 7 days worth of blocks. Proxy nodes are not consensus nodes, so we don't have to worry about having every single block. In fact, creating database checkpoints and deleting old blocks to free up disk space would totally be an option.
How does this help us create permissionless tokens on Hive?
Remember the example I gave where I transferred a million LEO tokens and allowed my old account to go negative while creating coins out of thin air on a new account? If everyone is running their own proxy node on a network like this, I would not be able to trick anyone with this transaction. Everyone in the network would know that my account was trying to push a bogus transaction and they would all flag me as a fraud by default.
Conclusion
The value of Hive blocks are extremely underestimated on this network. If we can find an efficient way to share block information (torrents combined with another "pyramid scheme" I have in mind) we can all run Hive database queries locally on our own machines. This will vastly reduce the bandwidth load on our precious full-nodes and allow us to dump that bandwidth burden in a decentralized fashion onto the ISPs. This creates a solution that essentially forces ISPs to run our network for free because we were already paying them a flat fee for Internet service in the first place.
In the posts to come I'd like to talk a lot more about specific strategies revolving around how to securely obtain block information and get to the main topic of the POB proof-of-burn tokenomics system that could arise out of all of this.
Return from POB Part 1: Distributed Proxy Nodes to edicted's Web3 Blog